


- Part 1: Introduction (this article)
- Part 2: Data and Graphs
- Part 3: AuthN & AuthZ
- Part 4: Unit & Integration Testing
(This article has been cross-posted to the Formidable Blog.)
Part 1: Introduction
Welcome to the first entry in a new series covering Async GraphQL in Rust! This series is aimed at intermediate Rust developers who have grasped the basics and are ready to build production-ready server applications. I'll cover a variety of topics, like:
- Handling GraphQL requests
- Accessing the database and pulling in related data
- Creating a GraphQL schema and building resolvers
- Authenticating and authorizing user requests
- Unit and integration testing
- GraphQL subscriptions and WebSocket events
- Builds, containers, continuous integration, and deployment
My demo application through this series will be "Caster" - a hypothetical tool to help podcasters, broadcasters, and streamers coordinate show content with their co-hosts and guests. It will be limited to just the API to support front end applications. I currently have an example API implementation for Caster written in Rust published to Github as bkonkle/rust-example-caster-api. You can use this repository to follow along as the series progresses.
Why Rust?

Rust is a low-level, statically typed, multi-paradigm programming language with a focus on memory safety, high performance, and reliable concurrency. It uses an innovative memory ownership and borrowing system to avoid the need for garbage collection, providing strong memory safety across threads and eliminating latency spikes due to garbage collection sweeps. It solves many of the same problems with mutability and undefined behavior that paradigms like Functional or Object-Oriented Programming do, but in uniquely different ways.
Rust doesn't check and collect memory at runtime. It tracks the lifetime of memory and who can read or write to it at compile time, and immediately frees the memory at runtime once it is no longer needed. Functions "own" the memory regions that variables represent. The default behavior when they are passed to other functions is to pass-by-value and move the value to the memory region controlled by the new function, which now takes ownership of that variable. If you don't want to hand over ownership of your variable, you can pass-by-reference to the other function and allow it to borrow the value, giving ownership back afterwards. The compiler uses the borrow checker to statically guarantee that references always point to values that haven't been dropped (the equivalent of garbage collected). This prevents problems with null pointer exceptions and undefined behavior.
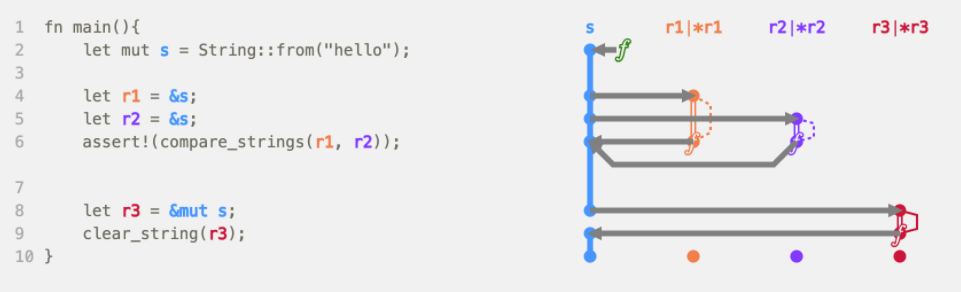
References can be mutable or immutable, but you can only have one mutable reference at a time. This prevents data race issues where multiple memory pointers try to access the same data at the same time, at least one of the pointers is writing to the data, and there is no synchronization method in use. This can cause unpredictable behavior that can be very difficult to troubleshoot at runtime. The safety provided can often rival the protection that languages with dependent types (like Idris) provide, but without the performance hit and extensive source code annotation burden they often come with.
Microsoft and Google both report that 70% of the security bugs they encounter are memory issues. Rust's goal is to match the freedom of memory access C or C++ provides, while applying sound type safety and enabling high-level abstractions with zero runtime cost (in most cases). It enforces strong memory safety even across threads by providing ways to share ownership with multiple locking methods.
The end result is a language that is fully compiled without heavy runtime support, has excellent memory safety, provides high-level features that modern developers have come to expect, and delivers spectacular performance while going easy on system resources and preventing chaotic runtime errors.
Why Async?
Async Rust is a long-awaited feature that has finally matured, and it was delivered in a way that has allowed a rich ecosystem to grow around the async tools available in the community. The primitive pieces of async support - Futures - can be leveraged a variety of different ways and are built upon by a few major competing libraries in the Rust community (like Tokio, async-std, and actix). Rust uses the popular async/await style to apply syntactic sugar to concurrency, presenting a developer experience that is very similar to synchronous code and is easy to work with.
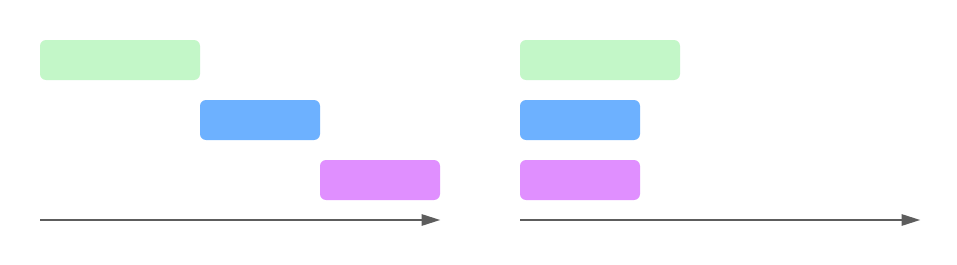
Async programming allows you to introduce concurrency in a single thread, waiting for multiple tasks to complete at the same time and not blocking execution to wait for each to finish in order. This is distinct from multithreading, which spawns multiple CPU threads to handle computationally expensive tasks in parallel. Async allows you to handle a large number of I/O-bound tasks that would otherwise have to spend a lot of time waiting for responses from other systems - like the filesystem or a network call - on a small number of OS threads. It requires significantly less CPU and memory overhead for systems with a lot of I/O-bound tasks, like the GraphQL API I'm building here.
Why GraphQL?

GraphQL has been my favorite way to enable client/server communication for a long time now. I was an early adopter within the JavaScript React and Node ecosystems, and I have continued to use it across other language communities because of the numerous benefits it provides over more traditional HTTP REST communication.
The built-in type system leads to a variety of ways to use it as a source of truth for automatic code generation, and makes it easy to define a contract of inputs and responses that the front and back end can unify on. The query language is very extensible, and the concept of connections to related data is a powerful tool to help the front end craft high-performance queries. The query language also provides the backend rich detail to help optimize queries, providing strong solutions to the N+1 problem with related data. Popular tools like Swagger and Postman aren't necessary, because rich documentation is built right into the schema and tools like GraphiQL make it easy to work with.
Rusty Crates

To present a highly maintainable project structure that has a great developer experience while staying async-first and providing the level of static and runtime safety we've come to expect from high-quality Rust applications, I take advantage of a number of excellent open-source shared community modules. Packages in Rust are called "crates", and the crates.io registry provides an excellent index for community crates that work with the popular Cargo package manager.
Tokio for Async
The Rust Future primitive is intended to be used with a runtime executor, which polls the task in order to drive progress. When polled, the Future advances as far towards completion as is possible in that moment, and then goes back into a pending state until polled again. This is where async runtimes come in - they provide an executor that spawns tasks within one or more threads, efficiently polls pending tasks, and synchronizes data between them.

The Tokio event loop is built on a very efficient multi-threaded scheduler, and it provides safe and reliable API's that protect against misuse. It supports an easy async/await interface, but also provides a lot of configurability to fine-tune performance for each use case.
Tokio's library follows conventions from Rust's standard library "when it makes sense". The async-std library is an alternative to Tokio that aims to more closely mirror the synchronous equivalents from the standard library. I avoided it because it hasn't been around as long, doesn't have as large of an ecosystem, and by most accounts is not as efficient as Tokio.
Warp for HTTP
Warp is built on hyper, which in turn is built on Tokio. Hyper is a fast HTTP client and server library with a focus on high concurrency with non-blocking sockets, and it performs extremely well on Rust server benchmarks. Warp provides a lightweight composable server framework to handle routing, parameters, headers, query strings, form data, WebSockets, logging, and more.
It integrates well with the async-graphql library I used for GraphQL communication, and it makes it easy to inject things like JWT token payloads into the request context.
GraphQL with async-graphql
The async-graphql library is a high-performance implementation of GraphQL built from the ground up to support async runtimes like Tokio and actix. Define your schema using Rust structs and automatically derive the GraphQL schema and query code, without needing to extend the Rust syntax and break rustfmt support. It provides many features that the popular alternative Juniper does not.
SeaORM for Database Access

I originally started out with SQLx, a pure Rust SQL toolkit built to support async which includes a unique compile-time checker that uses an active database connection. When I needed to build out highly dynamic queries I needed to support the flexible GraphQL schema I had designed, I found the fully-static approach of SQLx to be quite challenging and verbose to work around.
SeaORM builds on top of SQLx, providing a full-featured tool to manage dynamic queries with effective unit testing to prove correctness. Similar to async-graphql, it provides traits that can automatically derive the database modeling code and doesn't rely on a domain-specific-language. In many cases you can reuse your async-graphql types as SeaORM models.
The first-class async support, the dynamic nature of SeaORM's queries, and the avoidance of a domain-specific language are what set it apart from the popular alternative, Diesel.
Oso for Authorization
Authorization decisions are important for almost every API. These decisions can often be tricky, and you may need related data from the database before you can sufficiently decide whether the requesting user should have access to the resources they want to work with. These decisions are often implemented as case-by-case imperative logic implemented in the body of a resolver or a controller, and they can be hard to maintain and keep consistent.

Oso is a cross-platform authorization library that provides a declarative policy language called Polar, inspired by the Prolog logic programming language. With the primitives that Oso provides, you can build up sophisticated rules using patterns like RBAC or ABAC and traverse relationships, using concise Polar definitions to express those rules in a tight, declarative format.
It has first-class support for Node.js, Python, Go, Ruby, and Java; along with early (sparsely documented) support for Rust. The rules engine itself is built as a compiled Rust library, allowing it to be easily embedded in many other languages. There's a hosted service in early-access right now, but using the open-source libraries in your app is "free for all, forever".
One of the main distinctives that set it apart from the popular OPA alternative is the fact that it is intended to be deployed as an embedded component within a larger application, as opposed to a separate service that sits outside of your API like OPA. In addition, Oso's Polar language is generally easier to understand and maintain than OPA's Rego language - which is also inspired by Prolog but with different design decisions.
Project Structure
My Rust project structure is influenced by the default project structure for the Nx build tool in the JavaScript ecosystem. It takes advantage of Cargo's workspaces feature to divide code into entry points - called "apps" - and business logic divided into library modules - called "libs".
In large organizations, I like to split my source code repositories up by teams and deployables. Projects that are maintained by different teams with separate code review groups should be in separate repositories. In addition, projects that are maintained by the same team but are deployed separately in very different ways (like backend API's vs. front-end UI's) should be in separate repositories.
Even given those divisions, however, your team will often have projects that have multiple entry points - like an API that has side-processes for task workers or convenience services. Or, you may have a single service that starts out as a monolith but over time breaks apart into multiple related services or sidecar processes. In these cases you will often have a large amount of shared business logic or data access code that would be challenging to refactor if it was initially kept in the same crate and needed to be split apart.
To mitigate this, any business logic that could conceivably be shared between multiple apps or sidecar processes should be kept in crates within the "libs" folder, and entry points within the "apps" folder should be limited to code that is entirely application-specific. This keeps things decoupled and flexible and leads to less refactoring when entry points change.
Cargo Workspaces
Cargo's workspaces feature does a great job of enabling workflows around the project structure described above. Workspaces share the same Cargo.lock file and output directory, but are split into separate crates with separate Cargo.toml files specifying dependencies. The top-level Cargo.toml can be as simple as this:
[workspace]
members = ["apps/*", "libs/*"]
Entry-points in the Rust community are typically considered "binaries", and shared code modules are considered "libraries". In this structure, binaries go in "apps" and libraries go in "libs". Shared dependencies across the members of the workspace will all use the same version, which saves space and ensures that the crates in the project will all be compatible with each other. Cargo allows you to check, build, and test all crates together using commands at the top level of the repository.
Workspace members are statically linked into binaries - meaning that they don't require separate lib files when executing the compiled binary. Cargo stores incremental build information about each one, however, speeding up the build process when particular crates haven't been touched in an iteration.
Makefile Madness
When you want to go beyond the simple check, build, and test commands that Cargo provides out of the box, you'll likely want to embrace a scripting tool that allows you to add custom commands to your Cargo workflows. My preferred solution here is cargo-make, which uses a Makefile.toml config to add additional workspace-aware build tasks to your Cargo setup.
I use it to enable commands like:
- db-create, db-migrate, db-reset - commands to manage the local database.
- docker-api - a command to run docker-compose commands to spin up supporting processes.
- integration - a command to run integration tests with proper flags and environment variables
Linting with Clippy
Clippy gives you a variety of different code quality and linting tools, similar to the popular eslint utility from the JavaScript ecosystem. I use a top-level config file in .cargo/config.toml to configure linting rules, which apply to all crates within the workspace.
Config with Figment
To manage hierarchical configuration between environments, I use the Figment library. This library allows you to load and override configuration values from various sources at runtime, and it supports the popular toml format used by tools like Cargo. It easily handles nested configuration values, plays well with serialization tools like Serde, and produces actual Rust structs.
Onward to Implementation
In my next post I'll cover how I use SeaORM within Services to manage business logic and data access, and how I use Resolvers and Object types to build up a GraphQL schema and handle user requests. After that, I'll cover how I pull authentication and authorization into the request context using features from Warp and async-graphql. I'll follow that up with an exploration of unit and integration testing, both of which are very important to ensure correctness in your deployed application. Then I'll move into the world of "realtime" events with GraphQL subscriptions and WebSockets. Finally, I'll cap off my series with a discussion around continuous integration and deployment.